Kaggle Wheatコンペからの学び 〜 物体検出コンペで当たり前に行われている(っぽい)こと
先頃、KaggleのGlobal Wheat Detectionコンペに参加しました。
大学の研究・仕事を通じてこれまで画像データに触れることがあまりなかったのと、エールビールが大好きな自分としては小麦を眺めているだけで幸せな気分になれたことから、参加することにしました。
結果は、コンペ終了直後時点で、2270の参加チーム中、138位でした。
(注:本コンペは、ライセンス問題に伴いコンペ終了直後の順位がどの程度確定的なものか不明瞭なので、「コンペ終了直後時点で」と書きます。別記事でライセンス問題については触れるかもしれません。)
ただその実態は、人様のNotebookをコピー&ペースト&継ぎ接ぎ、Discussionのアイデアを目を皿のようにして読み込んでパクる、の連発だったので、良い意味で自分の実力と言えるかは甚だ疑問です。
しかし、初めて物体検出コンペに参加し、私見ですが何が当たり前に行われているのかまでは把握できた気がするので、以下メモします。
問題設定・データ概要
簡単に問題設定に触れておきます。
世界各地で撮影された小麦たちの画像から、小麦の頭部を検出するタスクです。クラスが1つの物体検出タスクとなります。

小麦の頭部を高精度に検出できれば、収量の予測であったり、天候不順などによる量やサイズの異常検知に役立つと考えられます。
小麦の数が多く容易に重なってしまったり、風の影響でぼやけてしまうといった画像そのものの検出の難しさに加え、小麦は世界各地で栽培されており栽培されている品種・環境などによる形状の違いもあるため、異なるロケーションでも汎用的に利用可能な検出モデルを構築することが求められています。
撮影されたロケーションは、訓練データ・テストデータ併せて11ある模様です。
訓練データは3422枚、公開されているテストデータは10枚です。
もちろん公開されている10枚のテストデータでスコアが計算され順位が決まるのではなく、公開されていないテストデータが1200枚程度あり、こちらでスコアが計算されます。
どのように公開されていないテストデータで評価が行われるのかというと、本コンペはコードコンペティションと呼ばれる形式で、少なくとも推論コードはKaggleのNotebookで作成する必要があります。
推論コードは必ず所定の形式のsubmisson.csvを出力するよう作成する必要があり、公開されているテストデータに対する推論を行ったsubmission.csvを提出すると、テストデータが公開されていないものに置き換えられてコードが再実行され、スコアが算出されます。
訓練コードは外部環境で作ってOKで、その場合学習で得たweightsをKaggleのDatasetにuploadし、推論コードで利用します。
訓練データの数が3000枚強と比較的少ないため、Data Augmentationが重要になります。
また、bboxが1つもない画像が50枚程度あったり、bboxが異常に大きい(面積の最大は529788!)・小さいものもあり、それらの前処理も必要となります。
さらに、テストデータのロケーション別の構成割合は、こちらで分析されており、原著論文のデータセットの情報から訓練データの構成を差し引くことで推測できます。

この分析から2点の事実が分かります。
- 訓練データとテストデータで、撮影されているロケーションに重複はない
- テストデータの中で、UTokyo_1で撮影された画像が8割近くを占める
1点目の事実から、本コンペではCVの結果よりも、LBの結果を信じた方が良いかもしれないと考えました。実際、Local CVよりもPublic LBの方がPrivate LBとの相関がありました。
もう1つ重要な点として、原著論文にあるように、コンペで与えられている1024 x 1024の画像は、より大きな画像からcropされたものになっています。

このことから何が言えるかというと、ジグソーパズルのように画像をつなぎ合わせて元の画像を再生すれば、そこから新たな訓練データを生成できることになります。(実装)
これは自分の場合もスコアアップに寄与したので、重要な発見だったと思います。
詳細なEDAについてはこちらが素晴らしいので、参考にしてください。
当たり前に行われていること
それでは以下、多くのソリューションで取り入れられている(と私には見えた)手法で、私も試行してみたものを列挙します。
- Dataの修正・追加
- Data Augmentation
- アーキテクチャの選択
- YOLO(コンペ参加直後に触っていた。v5はライセンスの問題で使用禁止に。単独ではおそらく最高精度が出せるモデルだった)
- EfficientDet(YOLOv5が禁止になってからはひたすらD5を中心にEfficientDetで実験していた。EfficientNetの考え方を取り入れた物体検出モデル。実装)
- 他は試してないが、DetectorRSやUniverseNetが良いなどの報告あり
- 高解像度で学習
- リサイズを行わず1024 x 1024の画像で学習(Colab Proではbatch size 1でギリギリCUDA out of memoryを回避できる)
- TTA(テストデータもaugmentation。実装)
- Pseudo Labeling (テーブルデータでもお馴染み、テストデータを予測し確信度の高いラベルのみ訓練データに取り入れて再予測。実装)
- Ensemble (精度を求めるKaggleではWBFが強い場合が多そう。実装, 解説)
上位ソリューション
列挙した手法を忠実に試すだけでも、時間さえとれれば銅メダル圏内くらいまでは行けると思いますが、銀・金圏を狙うならこれでは足りないと思います。
そこで弱々勢がやるべきことは、とにかく上位ソリューションから学ぶことだと思います。有難いことに素晴らしい解法をシェアしてくださっている方がいらっしゃいます。簡単に邦訳しておきます。
1st place solution
Summary
- MMDetectionフレームワーク上で様々なモデルを試した
- 試したアーキテクチャ:GFocal, ATSS, UniverseNet, DetectorRS, SOLO-v2
- 最終的にアンサンブルの対象とした最高精度のモデル
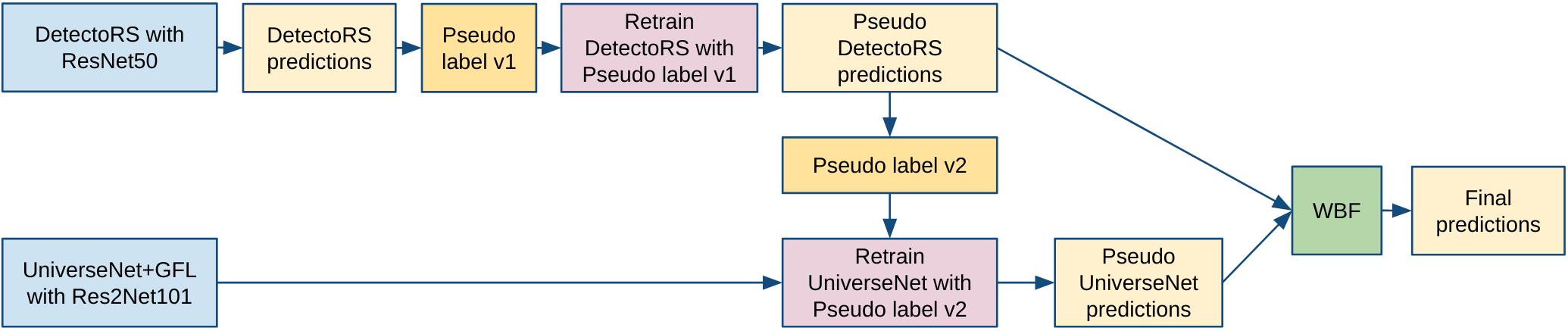
- DetectoRS with the ResNet50 backbone (https://github.com/joe-siyuan-qiao/DetectoRS)
- UniverseNet+GFL with the Res2Net101 backbone (https://github.com/shinya7y/UniverseNet)
- 各々でPseudo Labelingを1ラウンド行いスコアを上げた。また汎化性能を上げるため十分なaugmentationを行った
"ジグソーパズル"
- "ジグソーパズル"によるdata augmentationを行い1330枚の画像を生成。但し、bboxは画像の境界線上にあるなどの理由で自動生成できなかったため、オフラインでbboxを生成した上でpseudo labelingでbboxを生成した
Validation
- MultilabelStratifiedKFold with 5 folds (https://github.com/trent-b/iterative-stratification)
- bboxの数、bboxの面積の中央値、画像のsourceに基づいてstratify
- パズルにより生成した画像が他のfoldに入ってLeakしないようにした
- 原著論文によると、訓練データのusask1, ethz1はテストデータのUTokyo1, UTokyo2, UQ1, NAU1とかなり異なることから、usask1, ethz1はvalidationには使わないようにした
- ただ、Local CVとLBは相関しなかったので、最終的にはLBを主に注視してパラメータのチューニングを行った
- 学習は最初の1 foldのみを使って行った
Augmentation
- Albumentationsによるaugmentation
- HorizontalFlip, ShiftScaleRotate, RandomRotate90
- RandomBrightnessContrast, HueSaturationValue, RGBShift
- RandomGamma
- CLAHE
- Blur, MotionBlur
- GaussNoise
- ImageCompression
- CoarseDropout
- RandomBBoxesSafeCrop(ランダムにN個のbboxを選び、それらが欠けないようにcrop)
- Image colorization (https://www.kaggle.com/orkatz2/pytorch-pix-2-pix-for-image-colorization)
- Style transfer (https://github.com/bethgelab/stylize-datasets)(スタイルには公開されている10枚のテストデータを用いた)
- Mosaic
- Mixup
- Multi-scale Training
外部データ
モデル
- DetectoRS with ResNet50とUniverseNet+GFL with Res2Net101をメインのモデルとした。DetectoRSはUniverseNetより少し精度が良いが非常に遅かった
- Single DetectoRS Public LB score without pseudo labeling: 0.7592
- Single UniverseNet Public LB score without pseudo labeling: 0.7567
DetectoRSでは以下を利用した:
- LabelSmoothCrossEntropyLoss with parameter 0.1
- Empirical Attention (https://github.com/open-mmlab/mmdetection/tree/master/configs/empirical_attention)
学習パイプライン

推論
全てのモデルでTTA x 6を行った:
- Multi-scale Testing with scales [(1408, 1408), (1536, 1536)]
- Flips: [original, horizontal, vertical]
- 後処理はNMS
Pseudo Labeling
- テストデータに対して推論を行い、確信度を
confidence = np.mean(scores > 0.75)により算出。confidenceが0.6を超えるもののみラベルした - source: usask1, ethz1と、mosaic, mixup, colorization, style transferなどでaugmentされたデータはpseudo labelingを行わなかった
- 1 epoch, 1 round, 1 stage
- Data: original data + 3 x pseudo test data
アンサンブル
- WBFによるアンサンブル
- DetectoRSとUniverseNetのスコアの分布が異なったので、scaling using rankdata (https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.rankdata.html) を行った
scaled_scores = 0.5 * (rankdata(scores) / len(scores)) + 0.5
- WBF parameters:
- weights=[0.65, 0.35] respectively for models [DetectoRS, UniverseNet]
- iou_thr=0.55
- score_thr=0.45
最終サブミットのパイプライン(0.7262 on Private LB and 0.7734 on Public LB)
行わなかったこと
- MMDetectionとYOLOV5のアンサンブル(YOLOv5が禁止されたため断念)
- MMDetectionとEfficientDetのアンサンブル(試す時間が足りず。時間があればWBFのパラメータをチューニングしスコアを改善できたと考えている)
行ったが効果がなかったこと
- Wheat Ears Detection Dataset: CVは改善したが、LBは改善せず
- 同一モデルに対する2ラウンド以上のPseudo Labeling
- Scale-aware testing(Waymo Open Dataset Challenge 2020の1st solutionで採用)
- DetectoRSとUniverseNetに対するRotate90 TTA
4th place solution
Summary
- 十分なaugmentation (Custom mosaic, Mixup)
- EfficientDet
- Faster RCNN FPN
- マルチスケールのモデルをWBFによりアンサンブル
- TTA x 8 (hflip, vflip, rotate90)
- Pseudo Labeling
Augmentation
- Custom mosaic
- 通常のcutmixでは2つの画像を合成するところを、4つの画像を合成した
- bboxのboarderの情報が保存されるようにcustomize
- Mixup
- RandomCrop, HorizontalFlip, VerticalFlip, ToGray, IAAAdditiveGaussianNoise, GaussNoise, MotionBlur, MedianBlur, Blur, CLAHE, Sharpen, Emboss, RandomBrightnessContrast, HueSaturationValue
外部データ
- wheat spikes (https://www.kaggle.com/c/global-wheat-detection/discussion/164346), for license please refer (https://www.kaggle.com/c/global-wheat-detection/discussion/164346#928613)
- wheat 2017 (https://plantimages.nottingham.ac.uk/) at post (https://www.kaggle.com/c/global-wheat-detection/discussion/148561#863159).
モデル
- 5 folds, stratified-kfold, splitted by source(usask1, arvalis1, arvalis_2…)
- Optimizer: Adam with initial LR 5e-4 for EfficientDet and SGD with initial LR 5e-3 for Faster RCNN FPN
- LR Scheduler: cosine-annealing
- Mixed precision training with nvidia-apex
スコア
Valid AP/Public LB AP
- EfficientDet-d7 image-size 768: Fold0 0.709/0.746, Fold1 0.716/0.750, Fold 2 0.707/0.749, Fold3 0.716/0.748, Fold4 0.713/0.740
- EfficientDet-d7 image-size 1024: Fold1,3
- EfficientDet-d5 image-size 512: Fold4
- Faster RCNN FPN-resnet152 image-size 1024: Fold1
- Ensemble 9 models above using wbf can achieve 0.7629 Public LB/0.7096 Private LB
Pseudo Labeling
- Base: EfficientDet-d6 image-size 640 Fold1 0.716 Val AP/0.7483 Public LB/0.6822 Private LB
- Pseudo labeling step1: Train EfficientDet-d6 10 epochs on trainset + hidden testset (output of ensembling) with mixup, load checkpoint from base: 0.7719 Public LB/0.7175 Private LB
- Continue train EfficientDet-d6 6 epochs on trainset + hidden testset (output of pseudo labeling step1) with mixup, load checkpoint from pseudo labeling step1 : 0.7754 Public LB/0.7205 Private LB
20th place solution
パイプライン
.png?generation=1596588070622865&alt=media)
Validation
usask_1の全データと他のsourceの一部データの663枚をvalidationデータに固定
Augmentation
Custom augmentation
- crop and pad: borderのbboxをcropするのは良くないと考え、borderのbboxとbbox内部の画像は除去した
- crop and resize
- resize and pad
- Color Transfer between Images
- mixup: 訓練データ中の2画像をmixupする代わりに、bboxのある画像とない画像をmixup
- Rotation
Albumentations
- A.HorizontalFlip(p=0.5),
- A.VerticalFlip(p=0.5),
- A.RandomRotate90(p=0.5),
custom augmentationと競合するのでmosaicは行わず
外部データ
- SPIKE dataset
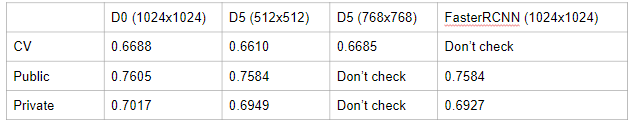
結果
上位ソリューションからの学び
学びしかないわけですが、その中で共通点を探してみると、訓練データの少ないコンペだったことから、Data Augmentationを十分に行ったソリューションが上位に来ている印象です。
augmentationの手法は様々ですが、albumentationsによるaugmentは行いつつ、加えて"ジグソーパズル"などを活用したcustomの手法でaugmentするのが重要だったようです。
customの手法以外では、mosaicは覚えておくべき手法だと思いました。(実装、解説)
おわりに
テーブルコンペ以上に、画像コンペは上位陣が神々のお戯れみたいになってる印象ですが、とは言え一般ピーポーでも基本に忠実にやっていけばメダル圏内までは行けるのかな、とも思いました。
本記事が、画像コンペやってみたいけどなんか怖い、という人の助けに少しでもなれば幸いです。